Building Scalable Performant And Cheap Distributed Applications Part 1
Do you constantly struggle to keep production running smoothly? Do you get a ton of alerts that don’t actually mean things are broken? Do you use Docker, but your deploy takes 20+ minutes? Do you use Docker, but manually configure Docker Hosts once the cloud provisions them? Does it take hours to bring a new server into the pool to help alleviate load? Have you never practiced failover to your database replica? Do you NOT know who owns your root DNS? Have you skipped that ticket about making an offsite backup, and now there isn’t one?
Do you practice DevOoops?
If you answer yes to any of these questions, then you just might… The thing is — you are not alone. Thousands of organizations do not have the time and resources to fix this type of technical debt, and escape the world of DevOops, where things just don’t run smoothly. That is despite using newest technologies (Docker), largest cloud in the world (AWS), and a great team of engineers.
I’d like to help.
Intentions and Audience
I regularly met engineers working for successful and profitable businesses, who admit to being confused and overwhelmed by the new tools coming out, seemingly every week.
Then there is another group — the “early adopters” — who truly believe to have found a panacea that solves all worlds problems, and preach it to everyone. Perhaps “Docker” comes to mind as a completely over-hyped technology enjoying a massive popularity bubble.
Finally, some engineers are just starting, but are already expected to put together infrastructure in production — and those can be the most overwhelmed bunch. And I can’t blame them.
How did we get here?
The world of web development had gone from tedious, but simple (think CGI + perl), to productive and magical (think Rails), to concurrent (think functional programming, Node, then Closure), to super available (think Erlang, Elixir — the latter attempting to combine productivity of Rails with concurrency and uptime of Erlang — successfully).
And this is just the backend — forget about the front-end and drop the operational aspect of the deploy, infrastructure configuration, automation, etc.
We’ve created a maze! Some call it “Micro Services Hell™“
Micro-Services (Hell? Or Paradise?)
So which group do I, Konstantin, personally belong? Funny you should ask. The thing is — I am a skeptical outsider, and always have been. I try things on, see if they fit, and use what I like. And I am also a bit overwhelmed, and very excited about what lies ahead. Humans are great at classifying a ton of complexity, and that is exactly what I plan on doing here. Because complete mayhem.
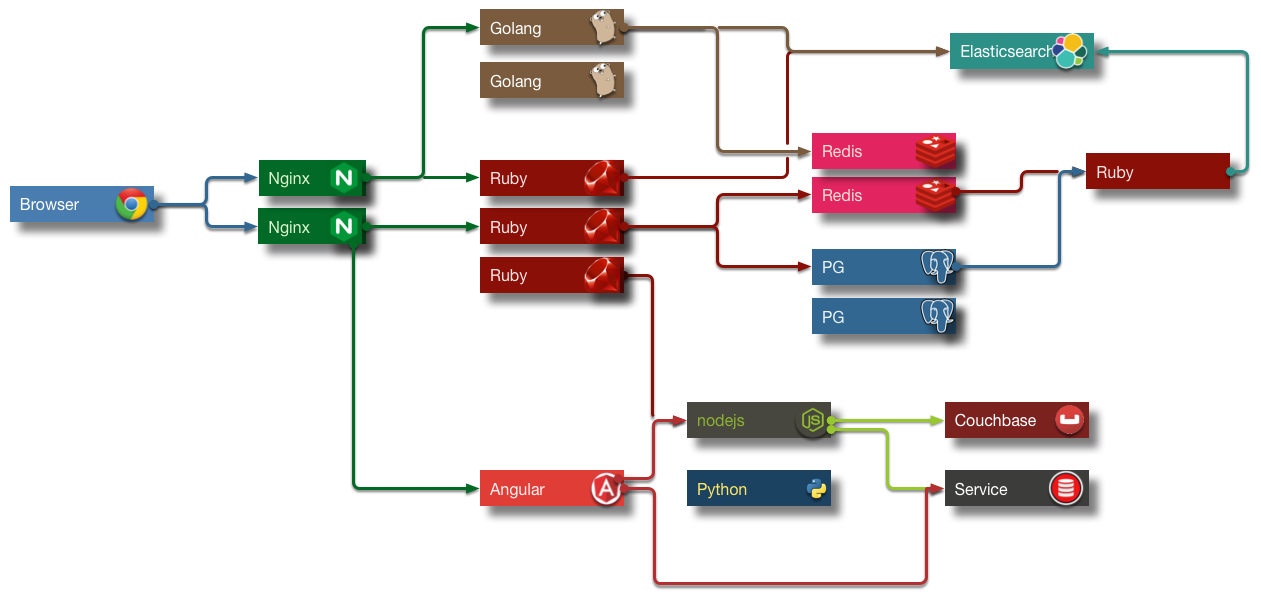
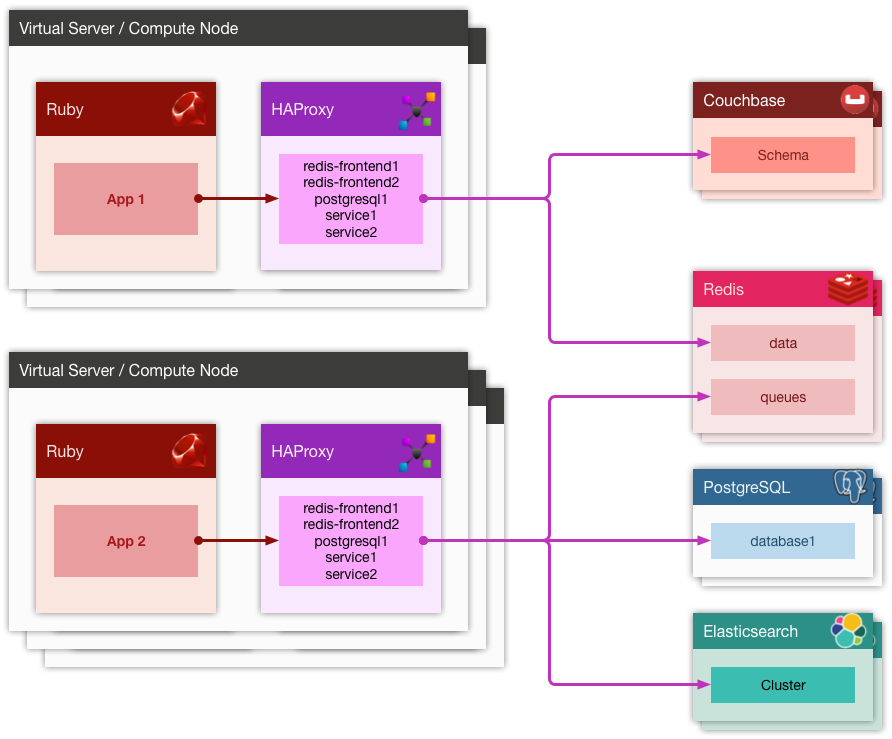
As can be see from the (fictional), but multi-color diagram above, building todays application requires connecting things to other things in many different ways. This requires things to know about other things, to be able to talk to them, and listen. Just like people. We would be worthless without these basic properties.
Cross-cutting Concerns
Too often when a new application is conceived, broken down to the features, stories, mockups, and then methodically implemented, we often forget to ask ourselves the fundamental questions about the requirements related to application availability, survivability, scale and performance, security, auditability, etc. We don’t have to implement ANY of these dimensions in the beginning, but thinking about them ahead of time informs so many turn-key decisions, related to software design, systems architecture, vendor selection, infrastructure cost, and even technology stack.
I do not suggest that we invest a ton of effort into making a non-existant application highly-available. I just want to have a having a conversation about what these requirements might look like in the future. I find this conversation to be very helpful.
Infrastructure and Innovation
When applications like Chef, Puppet and Ansible came to the rescue, when it comes to configuring servers, we finally reached a point of automating servers that were running our software (well, maybe not all of us, but some did).
And now Docker and light-weight containers are offering something different, and when coupled with the ability to run on bare metal — very exciting indeed.
But all of this is changing so rapidly. What to use? What to apply? What are the best practices?
Oh, these are already yesterday’s best practices?
Well, who has the ones that will still be best tomorrow?
Back into the Future: Let’s Start a new Company!
This part is hypothetical.
Say we are building a brand new web application that will do this and that * in a very *particularly special way, and the investors are flocking, giving us money, and so we get funded. W00T!
If I am an early engineer, or even a CTO, on this new project, I would not be doing my job if I am not asking the founders a lot of questions that affect hugely the ways we are going to build the software supporting the business. And how soon.
So I pull the founder into a quiet room, hide their cell phone from them, and unload onto them with questions for an hour.
The best hour spent in the history of this startup. Promise.
Six Questions to ask Every Founder
. How reliable should this application be? What is the cost of one hour of downtime? What’s the cost of one-hour downtime now, six months from now, a year from now? What is the cost of many small downtimes? What about nightly maintenance?
. How likely is it that we’ll get a spike of traffic that will be very important or even critical for the app to withstand? Perhaps we were mentioned on TV. Or someone twitted about us. How truly bad for our business will it be, if the app goes down during this type of event because it just can’t handle the traffic? And even if the spike of death happens, how important it is that the team can scale the service right up with traffic within a reasonable amount of time? What is a reasonable amount of time?
. How important is it that the application interactions are fast? Or that the users don’t have to wait three seconds for each page to load? How important is it that the application performance is not just “good” (say, 300ms average server latency), but outstanding (say, 50ms server average latency)?
. How important it the core application data is to the survival of the business? For example, a financial startup that deals with people’s money, data integrity is paramount. For a social network that’s merely collecting bookmarks, it’s only vaguely significant. Large data losses are never fun, but a social network might recover, while a financial service will not.
. How important it is that the application is secure? This question should be viewed from the point of view of being hacked into — once you are hacked, can you recover? If the answer is “no”, you better not get hacked. Right?
. The last bucket will deal with the engineering effort. Things like cost, productivity, ability to release often, hire and grow the team easily, etc. What’s the cost of maintenance, how big is the Ops team, how big and how senior must be the development team?
Oh, I hear you say the word: “catastrophic”
Now, how bad is it for your business, if, say, you are hosted on AWS, and a greedy hacker takes over your account and demands ransom? Well, if you did not think about the implications of building a ‘mono-cloud’ service, and even your “offsite” backups are performed in your one and only AWS account, then the answer is — once again — catastrophic. Your business is terminated.
But then, in between “oh, it hurts, but it’s ok” and “we are finished” there lies a whole other category of: “our users are pissed”, “we lost 20% MOU”, “everyone is switching to another social network”, “did you hear so and so got broken into and got their user data stolen? They’ve asked for my social security number, and I am furious!…”
[WARNING] This may not be The Catastrophy just yet, but your technology is either not scaling, not reliable, or not secure. The Catastrophy may be right around the corner.
Given that I’ve been building almost exclusively applications that most certainly did not want to die because of scalability, reliability or security concerns, I’ve applied the same patterns over and over again, and results speak for themselves. I don’t like bragging, and I wouldn’t say this — but for those of you still skeptical — I refer you to the uptime and scalability numbers mentioned in this presentation.
Which brings me to the conclusion of this blog post.
Six Critical Tenets of Modern Apps
The topics and scenarios above, distill down to the following principles the apply to the vast majority of applications built today.
As a simple exercise, feel free to write down — for your company, or application — how important, on a scale from 0 (not important), to 10 (critical/catastrophic if happens), are the following:
. High Availability. Solutions to this are comprised of fault tolerance, multi-datacenter architecture, offsite backups, redundancy at every level, replicas, hosting/cloud vendor-independence, monitoring and a team on call. . Scalability. Scalability is the ability to handle a massive concurrent load, perhaps hundreds of thousands of actively logged in users interacting with the system; that might spike to (say) 1M or more. It is also the ability to dynamically raise and lower application resources to match the demand and save on hosting. . Performance. What’s the average application latency (the time it takes the servers to respond to a user request — like a page load)? What’s the 99% and 95% percentile? This is all application performance. Good performance helps scalability tremendously but does not warrant scalability in of itself. Well-performing applications simply need a lot fewer resources to scale, and are both the pleasure to use by your customers, and cheap to scale up. So performance truly does matter. . Data Integrity. This is about not losing your data. Accidentally. Or maliciously. Usually, some data can be OK to lose. While another set of data is the lifeblood of your business. What if a trustworthy employee, thinking that they are connected to a development database, accidentally drops a critical table, and only then realizes that they did that on production? Can you recover from this user error? . Security. This one is a no-brainer. The bigger the payoff for the hackers (or disgruntled employees) the more you want to focus on securing your digital assets, inventions, etc. Not only preventing them from being copied and stolen but from being erased altogether. Always have at least the last day’s backup of your database securely downloaded somewhere into an undisclosed location and encrypted with a passphrase. . Productivity. How quickly do we need to move? How unproven is the idea? Is it better to be down often, but move with a super-sonic speed, or be slower, but more reliable?
These types of trade-offs I would like to discuss in the next installment of the DevOops Series. // //== Coming Up Next // //In the next blog post, I will discuss specific solutions to: // //* High Availability // ** Fault tolerance // *** Redundancy // *** Recovery // *** Replication //* Scalability // ** How to scale transparently to more traffic // ** And scale down as needed //* Service Discovery // ** How does the app know where is everyone? //* Monitoring and Alerting // ** How to put your entire dev team on call // ** How to alerts on what’s important //* How to do this all at a fraction of a cost that it used to be just a few years ago… //* How to stay vendor independent and why would you want to. // //Thanks for reading!
Comments