Evaluating Terraform for DevOps Engineers
In this post we dive deep into a comparison between Terraform, Chef & Puppet, talk at length about module dependency management, see what’s a simple Terraform config, and what you need to do as you scale out your infrastrucutre.
I come from doing large-scale DevOps highly effectively with Chef, and I grew to like it. There, the model was based on a “centralized” architecture. Terraform is not. Understanding how they differ and where they are similar with help you get up to speed with Terraform, if you are already familiar with other infrastructure or configuration management software.
In any case these tools help us deploy what’s commonly called “Infrastructure as Code”, or DevOps, so let’s take a look at whether we get what we were promised…
The Dev Against the Ops Problem
This brings us to the conversation about DevOps, because I saw how it was born in front of own eyes out of the real pain that I remember clearly, like it was yesterday.
Because, dear reader, before DevOps there were just Dev and Ops. And let me tell you that the people working as software developers and people in charge of “operations”, i.e. “production” were in a constant state of war. Mind you, this was before the Public Cloud proliferation, so the Ops people were often tasked with setting up servers in the datacenter.
And while there is a certain push for the comeback to “bare metal”, i.e. to self-hosted data-center based hardware, the move to Cloud took away the “provisioning” headache, and with it often the entire reason for the Ops to exist.
We should be asking ourselves one important question: why was there a war between engineers and operations people?
The War between Dev & Ops
If you were hired as an Operations Engineer — your job was to procure hardware, install it at the data-center, configure the networking and firewalls, and then keep things running — “up”, and that meant keeping them stable and minimizing change. What the Ops team was running was typically a custom-made web application, which Ops folks did not understand and could not fix when they broke. And engineers often times weren’t even on call. These practices created a lot of distrust between ops and engineering.
At the same time, lean startup methodology was telling founders to iterate and fail quickly, as to learn and pivot, rinse repeat until your business model works. All of that meant that until we were successful, the risk of crashing the site was acceptable to business if it meant continuous and rapid delivery of new features.
NOTE
Unfortunately, that proved a difficult pill to swallow for many seasoned sysadmins and network engineers, who were used to delivering rock-solid infrastructure that ran finished products like Oracle, or SAP. The startup culture did not need or want anything to resist the continuous delivery of new features, and that meant the Ops either had to adapt and become full-fledged engineers, or find work elsewhere.
This tension was well described in the most excellent book on Site Reliability Engineering: How Google Runs Production Systems, which contains much additional wisdom from Google’s point of view.
DevOps — What Do We Want From It?
DevOps movement coincided with the general availability of public cloud. The cloud removed the need to manage anything in the data center, and without the data center all that was left to configure is severs on the cloud. And this was a lot closer to what experienced Software Engineers already knew how to do.
And so around 2007-2008 the devops movement meant that a newly formed startup did not have to hire a single Ops person. Some of the startups adopted IaC (Infrastructure as Code) mantra, and the infrastructure code was finally committed to a git repo, often changed, and deployed.
The engineers at Wanelo, as an example, learned and delivered Chef recipes and cookbooks that configured components on the cloud together with delivering their feature in Rails.
Reaching DevOps Nirvana
In the years 2012-2015 when I was a CTO at Wanelo we went all the way Chef.
We created three non-overlapping environments: dev, staging and production.
Staging and Production were identical, except staging was way smaller. We could try the new Chef cookbook on Staging, and only after confirming it works would we apply it to production.
This often required cloning the repo three times (one per environment) and configuring Chef’s environment authentication per folder. That was a bit clunky, if I am being honest.
What “Chef” was Great At
As it turned out, having a central database of all of your servers, their roles, and cookbooks that installed various components, made completely automatic configuration of the newly booted servers possible.
But, and this is an important but — we had to first provision the EC2 server using aws CLI or web UI, and only then could Chef connect and install itself, and then run pulling all the tasks from the cental server, and then running them until the machine came up with the application (if that was its role) or some other software dictated by the role assigned to the machine.
TIP
As an example: when we configured our load balancers, we configured nginx to be a front-loading HTTP/HTTPS service, routing requests to a local haproxy instance, with the configuration file generated entirely by Chef. The haproxy recipe performed a search for all servers marked with the “app-web” role, and added them to haproxy’s backend. As we added or removed the servers, by say deleting them, haproxy would first blacklist them as they were unresponsive, and once they were removed from Chef, and chef-client ran on load balancers, the dead server entries would be removed from the backend in the haproxy config file.
This ability to search for a particular role, automate routing of all requests in the system using Chef was a pinnacle of my personal DevOps experience.
Since then, I re-created similar Chef-based deployments of Rails applications at least three more times, at three different companies. There was not a single thing in the cloud that was manually configured. Everything was done via Chef, and the codebase was git-committed, peer-reviewed and even had automated tests.
I felt that 100% automation that Chef gave us was incredibly awesome, especially considering manual ways before it. But Chef was not without its own problems.
Where Chef Lacked
One big complaint about Chef is that it mutates infrastructure. Chef runs once every 30 minutes, and in theory is able to modify the servers it was running on.
On top of that, Chef had no knowledge of any manual modifications performed to any server. This sometimes created drift between servers, and we’d have to replace some of the instances.
NOTE
Personally to me mutable infrastructure did not present any clear and present danger, because we never changed production servers without applying this change via Chef. However, less disciplined organizations most likely ran into major problems with this.
The second thing that Chef really sucked at was provisioning new resources, even as simple as EC2 instances. We had to use aws CLI to provision our servers, and Chef’s bootstrap mechanism to get Chef installed there, and subsequently whatever configuration is appropriate for that role(s).
This gap between configuration management and infrastructure provisioning is exactly what Terraform was designed to solve.
Why Configuration Management Tools Fell Short
Configuration management tools like Chef and Puppet had several limitations for modern cloud infrastructure:
- Infrastructure Provisioning Gap: These tools configured servers but couldn’t create the underlying cloud resources (VPCs, databases, load balancers)
- Mutable Infrastructure: Changes were applied to existing servers, leading to configuration drift over time
- Bootstrap Complexity: Getting the initial configuration management agent installed and connected was often brittle
- Limited Cloud Integration: They weren’t designed to leverage cloud-native APIs for resource management
Terraform Intro
Hopefully you already know the basics: that Terraform is a tool for building, changing, and versioning infrastructure. Terraform can manage cloud infrastructure for most popular cloud providers as well as custom in-house solutions.
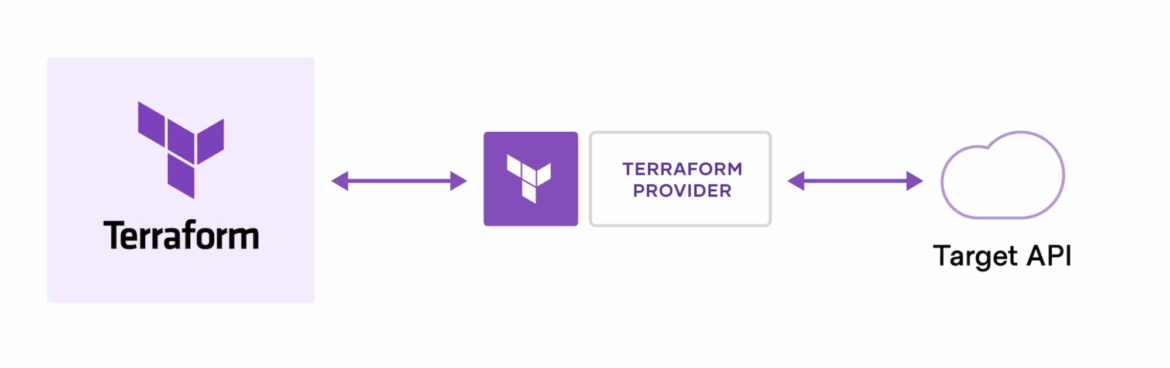
Terraform accomplishes this by offering a declarative configuration language HCL, which gives users the ability to describe the desired state of the infrastructure — i.e. “what I’d like to have running”.
Notably, HCL never descibes HOW this infrastructure should be provisioned, because “HOW” is the responsibility of the Terraform executable. It only descibes the “WHAT” should be the desired outcome.
Terraform executable reads HCL file, and constructs a tree of actions (some of which maybe interdependent) to perform against the Cloud Native API on behalf of the user to achive the desired state.
In a nutshell — Terraform is a convenient Facade for Cloud Native APIs.
Terraform Providers
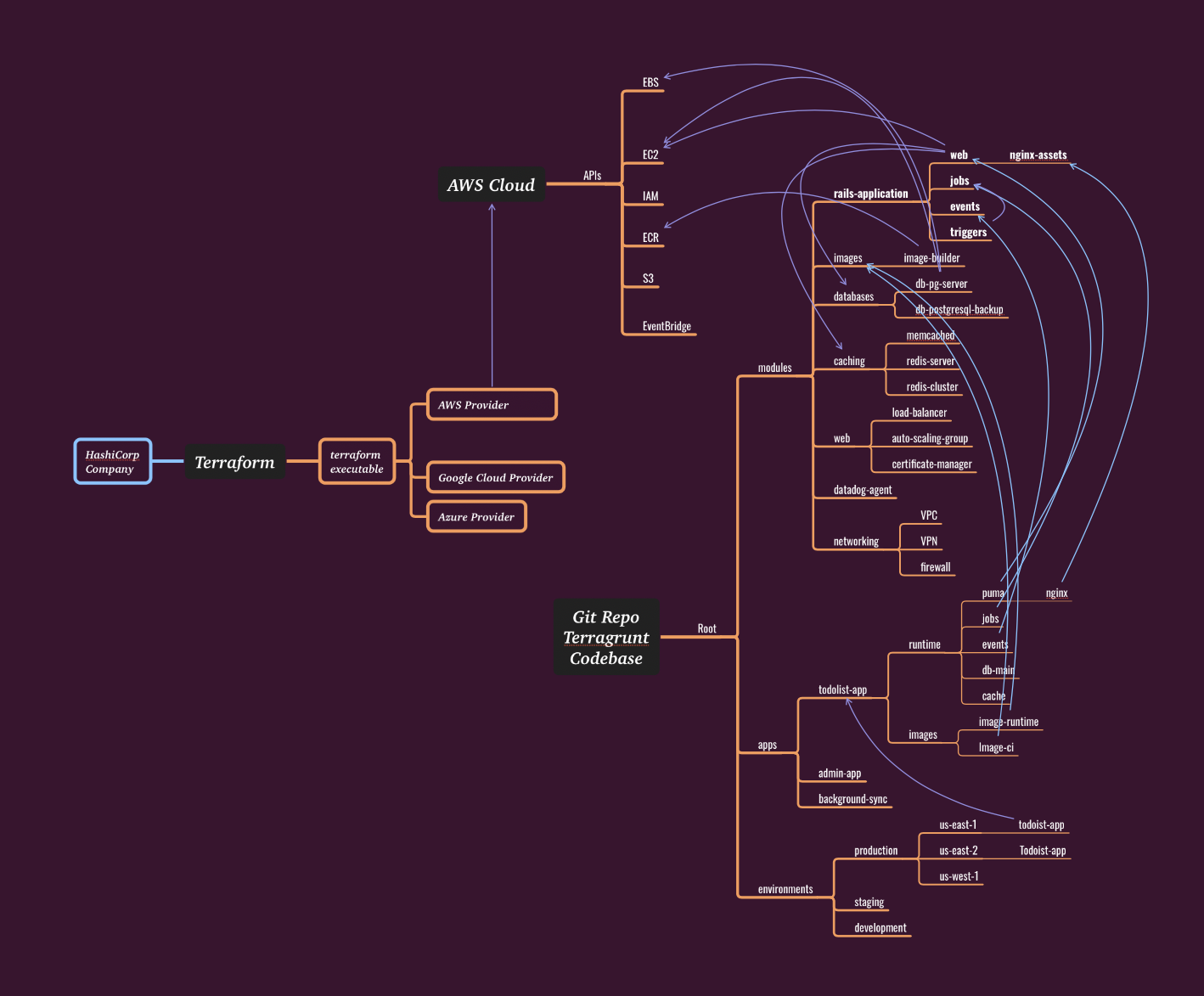
We’ll build out a diagram that, hopefully, will assist in understanding how Terraform fits into the picture.
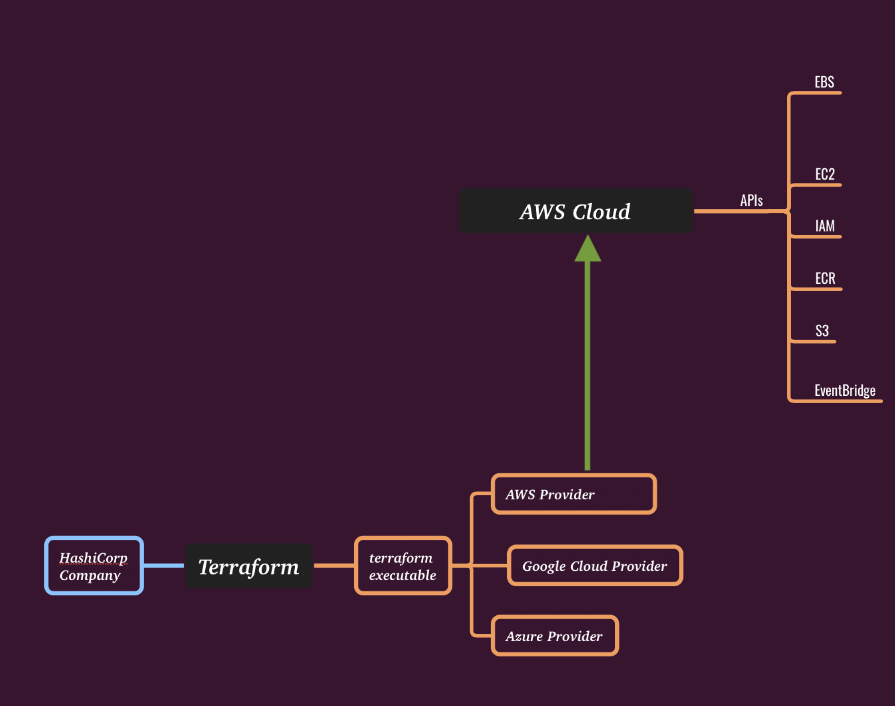
This first diagram shows how Terraform binary, using a “plugin architecture” design pattern, is able to load a specific adaptor for any specific cloud. Terraform allows us to define desired resources in a consistent declarative language, HCL. That achieves some uniformity among infrastructure as code efforts.
In reality, however, each cloud is done so differently that there is no universal Terraform language that is Cloud-agnostic. Terraform can speak to every cloud for which a provider has been written. But Terraform can only deal with resources and actions that are available in that particular cloud, and supported by the given provider.
Terraform is Not Cloud Agnostic
For example, to create a virtual instance in:
- Google Cloud — one must use a resource called
google_compute_instance - AWS – one must use a different resource
aws_instance
Terragrunt & Infrastructure as Code Repos
What Terraform is Not
It’s worthwhile to say what Terraform isn’t:
-
While Terraform works with pretty much any cloud these days, it is not cloud-portable, because HCL resource definitions are often tied to the specific cloud they belong to. For example you will find that the
awsprovider gives access to many AWS resouces, but they are all universally named with theaws_prefix, as not to confuse them with Azure or GCP resources: for example,aws_instance,aws_security_group,aws_vpc, etc. +While the language (HCL) remains the same when describing infrastructure on AWS or Google Cloud, if you do migrate from one to another you will need to redefine all of your resources via the resources of the new cloud.
-
Terraform isn’t a configuration toolkit. you provision your resource (which can be a server, a queue, an RDS database), but for a virtual server you dont have install software on it, or start something up: the most common task done with Chef. These days people seem to be using Ansible for this purpose, once the Terraform resource is up.
Cloud Native API
One of the main distinguishing aspects of Terraform compared to pretty much any other “previous-generation” DevOps automation is that terraform is a compiled binary executable written in Go. It’s main purpose is to “leverage the rich Cloud Native APIs that are provided by the cloud providers”.
For instance, for AWS Terraform will download an “aws” module which contains AWS-specific resources, together with the code that knows how to use AWS API to create, modify, and delete those resources.
Terraform never goes out to SSH into the host, like Chef did. It sits outside of your Cloud environment, and controls your infrastructure by making API calls to the cloud provider, and comparing it to the state file.
Whenever you modify Terraform resource descriptions in your *.tf files and run terraform plan, it will compare three things:
- Using AWS API it will query the objects defined in the local HCL files.
- It will also read the state of these objects from the Terraform State file. **Normally, these two will be the same. If they are not — it means someone made manual modifications to these resources in AWS, and that creates what’s known as a “drift”. ** In this example lets assume you don’t have any drift.
- Finally — it will read the desired state as described by your local HCL files.
Terraform will then compare 1 & 3 to show you the difference (and it will warn you about any differences between 1 & 2).
Any changes you made locally should show up as difference. Running terraform apply will use AWS API to modify appropriate resources, this syncing the state file with the actual state of the infrastructure and the HCL template.
Terraform State
Terraform keeps track of the state of the infrastructure it manages. This state is stored in a file named terraform.tfstate. This file is created after the first terraform apply command is run, and is updated every time Terraform is run.
For teams larger than one, it is recommended to store the state file on S3. For more information on the best practices related to state management please read about How to Manage Terraform S3 Backend on the Spacelift blog.
Directories
I’ve skipped the very basics on how to do plan and apply, as well as init because there are a ton of literature on how to get that setup.
What I want to talk about in this post is how Terraform Project should be organized, and how directories with
*.tffiles relate to each other, and more importantly — how they link to the infrastructure in the Cloud.
Code Example
Below is a very simple example of Terraform configuration file that creates an AWS EC2 instance and a security group:
provider "aws" {
region = "us-west-2"
}
resource "aws_instance" "example" {
ami = var.instance_ami
instance_type = var.instance_type
vpc_security_group_ids = [aws_security_group.example.id]
user_data = <<-EOF
#!/bin/bash
echo "Hello, World" > index.html
nohup busybox httpd -f -p 8080 &
EOF
tags = {
Name = var.instance_name
}
}
resource "aws_security_group" "example" {
vpc_id = "vpc-12345678"
ingress {
from_port = 3000
to_port = 3000
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}# Directory: `ec2instance`
# File: `variables.tf`
variable "instance_type" {
description = "AWS Instance Type"
default = "t2.micro"
}
variable "instance_ami" {
description = "AWS Instance AMI"
default = "ami-0c55b159cbfafe1f0"
}
variable "instance_name" {
description = "AWS Instance Name"
default = "terraform-instance"
}What’s cool about the above declaration is that can be used as a module to create instances of any type that belong the hardcoded VPC.
We can then use this module in another project (directory) where we would invoke it while setting its variables to the desired values:
module "ec2instance" {
source = "../modules/ec2instance"
instance_type = "t2.large"
instance_ami = "ami-0c55b159cbfafe1f0"
instance_name = "terraform-instance-1"
}File Naming Conventions
When you look at the above example it seems pretty clear. What doesn’t seem clear is how to grow this systems architecture. What if we want to add a load balancer, a database, a cache, and a few more instances?
NOTE
In the Chef world, you have reusable “cookbooks”, while in Terraform we have “modules”. Module is typically a set of *.tf files in a single directory. The files in that directory should follow a naming convention, for example, common files are:
main.tf— the main file that defines the module and most resources neededvariables.tf— input variablesoutputs.tf— output variableslocals.tf— local variablesdata.tf— read only resources that are results of TF querying the cloud provider
If the module is, say, AWS-specific, then you may also find files such as:
iam.tf— defines necessary IAM roles and policiess3.tf— defines S3 bucketsrds.tf— defines RDS instancesec2.tf— defines EC2 instancesalb.tf— defines Application Load Balancers- and so on…
Directories, Modules, and State
One of the most surprising discoveries when learning Terraform is understanding how directories, modules, and state files relate to each other. This is fundamentally different from Chef’s centralized model and can catch newcomers off-guard.
The Directory-State Relationship
Each directory containing *.tf files maintains its own separate state file. This is a crucial concept that isn’t immediately obvious:
my-terraform-project/
├── networking/
│ ├── main.tf
│ ├── variables.tf
│ └── terraform.tfstate # State for networking resources
├── database/
│ ├── main.tf
│ ├── variables.tf
│ └── terraform.tfstate # State for database resources
└── compute/
├── main.tf
├── variables.tf
└── terraform.tfstate # State for compute resourcesThis means when you run terraform apply in the networking/ directory, it only knows about and manages the resources defined in that directory’s *.tf files. It has no knowledge of resources defined in database/ or compute/ directories.
The Dependency Challenge
This isolation creates a fundamental challenge: How do you handle dependencies between directories?
Consider a typical infrastructure setup:
- VPC and Subnets (networking layer)
- RDS Database (needs VPC subnets)
- EC2 Instances (needs VPC subnets and database connection info)
Since each directory has its own state, how does the database/ directory know which VPC subnets were created by the networking/ directory?
Solution 1: Remote State Data Sources
Terraform provides terraform_remote_state data sources to reference outputs from other state files:
networking/outputs.tf:
# networking/outputs.tf
output "vpc_id" {
description = "ID of the VPC"
value = aws_vpc.main.id
}
output "private_subnet_ids" {
description = "IDs of the private subnets"
value = aws_subnet.private[*].id
}database/main.tf:
# Reference networking state to get VPC information
data "terraform_remote_state" "networking" {
backend = "s3"
config = {
bucket = "my-terraform-state"
key = "networking/terraform.tfstate"
region = "us-west-2"
}
}
resource "aws_db_subnet_group" "main" {
name = "main"
subnet_ids = data.terraform_remote_state.networking.outputs.private_subnet_ids
tags = {
Name = "Main DB subnet group"
}
}The Application Order Problem
With separate directories and state files, you now face the dependency ordering problem:
- You must apply
networking/beforedatabase/ - You must apply
database/beforecompute/ - If you need to destroy infrastructure, the order reverses
Manual Dependency Management:
# Correct application order
cd networking/
terraform apply
cd ../database/
terraform apply
cd ../compute/
terraform apply
# Correct destruction order (reverse)
cd compute/
terraform destroy
cd ../database/
terraform destroy
cd ../networking/
terraform destroyThis manual process is error-prone and doesn’t scale well for complex infrastructure with many interdependencies.
Solution 2: Monolithic State (Not Recommended)
You could put everything in a single directory with one state file, but this creates other problems:
- Blast radius: Any mistake affects all infrastructure
- Team collaboration: Multiple people can’t work on different components simultaneously
- Apply time: Every
terraform planchecks all resources, even unchanged ones - State locking: Only one person can apply changes at a time across all infrastructure
The Need for Dependency Management
This is where the limitations of vanilla Terraform become apparent. Managing dependencies manually across multiple directories is:
- Error-prone: Easy to apply in wrong order
- Time-consuming: Manual tracking of what depends on what
- Fragile: Changes in one directory can break assumptions in others
- Not scalable: Becomes unmanageable with large, complex infrastructure
This dependency challenge is exactly what tools like Terragrunt were created to solve.
Terragrunt: Solving Terraform’s Dependency Problem
Terragrunt is a thin wrapper around Terraform that provides tools for working with multiple Terraform modules. It was created by Gruntwork to address many of Terraform’s limitations around:
- Dependency management between modules
- DRY (Don’t Repeat Yourself) configurations
- Remote state management
- Locking and encryption
How Terragrunt Manages Dependencies
Terragrunt introduces a terragrunt.hcl configuration file that can specify dependencies between modules:
File Structure with Terragrunt:
infrastructure/
├── networking/
│ ├── main.tf
│ ├── variables.tf
│ └── terragrunt.hcl
├── database/
│ ├── main.tf
│ ├── variables.tf
│ └── terragrunt.hcl # Declares dependency on networking
└── compute/
├── main.tf
├── variables.tf
└── terragrunt.hcl # Declares dependencies on networking & databasenetworking/terragrunt.hcl:
terraform {
source = "."
}
remote_state {
backend = "s3"
config = {
bucket = "my-terraform-state"
key = "networking/${path_relative_to_include()}/terraform.tfstate"
region = "us-west-2"
encrypt = true
dynamodb_table = "terraform-locks"
}
}database/terragrunt.hcl:
terraform {
source = "."
}
# Declare dependency on networking module
dependency "networking" {
config_path = "../networking"
mock_outputs = {
vpc_id = "vpc-fake-id"
private_subnet_ids = ["subnet-fake-1", "subnet-fake-2"]
}
}
inputs = {
vpc_id = dependency.networking.outputs.vpc_id
subnet_ids = dependency.networking.outputs.private_subnet_ids
}
remote_state {
backend = "s3"
config = {
bucket = "my-terraform-state"
key = "database/${path_relative_to_include()}/terraform.tfstate"
region = "us-west-2"
encrypt = true
dynamodb_table = "terraform-locks"
}
}Terragrunt Dependency Resolution
With Terragrunt, you can now run:
# Apply everything in correct dependency order
terragrunt run-all apply
# Destroy everything in reverse dependency order
terragrunt run-all destroy
# Plan all modules
terragrunt run-all planTerragrunt automatically:
- Analyzes the dependency graph across all modules
- Determines the correct application order
- Applies modules in parallel where possible (no dependencies)
- Handles failures gracefully by stopping dependent modules
Additional Terragrunt Benefits
DRY Configuration: Terragrunt can generate provider configuration, avoiding repetition:
# terragrunt.hcl (root level)
generate "provider" {
path = "provider.tf"
if_exists = "overwrite_terragrunt"
contents = <<EOF
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = "us-west-2"
}
EOF
}Mock Outputs for Development:
The mock_outputs feature allows you to work on dependent modules even when dependencies aren’t deployed yet.
Built-in Remote State Management:
Terragrunt automatically configures S3 backends with DynamoDB locking, eliminating boilerplate.
When to Use Terragrunt
Use Terragrunt when:
- You have multiple Terraform modules with dependencies
- You’re working in a team environment
- You want to avoid duplicating provider and remote state configuration
- You need to deploy/destroy infrastructure in dependency order
Stick with vanilla Terraform when:
- You have simple, single-module infrastructure
- Dependencies are minimal or easily managed manually
- You prefer to avoid additional tooling complexity
Conclusion: From Chef’s Centralization to Terraform’s Distribution
The journey from Chef to Terraform represents a fundamental shift in infrastructure management philosophy:
Chef’s Centralized Model:
- Single source of truth (Chef Server)
- Automatic discovery and configuration
- Built-in dependency resolution
- But: Single point of failure, mutable infrastructure, brittle bootstrapping
Terraform’s Distributed Model:
- Declarative, immutable infrastructure
- API-driven, no agents required
- Isolated state per directory/module
- But: Manual dependency management, learning curve for state management
The Terragrunt Solution:
- Combines Terraform’s strengths with dependency management
- Maintains the distributed, immutable benefits
- Adds the automation and orchestration capabilities
Understanding the directory-state relationship and dependency challenges in Terraform is crucial for anyone transitioning from Chef/Puppet or building complex infrastructure. While Terraform’s isolated state model can seem daunting at first, tools like Terragrunt provide elegant solutions that maintain the benefits of Infrastructure as Code while solving real-world operational challenges.
The key insight is recognizing that each Terraform directory is its own isolated universe, and planning your module structure and dependencies accordingly. This fundamental understanding will save you countless hours of debugging and frustration as you scale your infrastructure automation efforts.
Comments